Deep Q-Networks and Beyond
Contact me
Blog -> https://cugtyt.github.io/blog/index
Email -> cugtyt@qq.com
GitHub -> Cugtyt@GitHub
本系列博客主页及相关见此处
来自Arthur Juliani Simple Reinforcement Learning with Tensorflow series Part 4 - Deep Q-Networks and Beyond
DQN相比普通Q-Network改进:
-
单层网络到多层卷积网络
-
实现Experience Replay,可以使用存储的经验记忆训练
-
使用第二个目标网络,用于在更新时计算目标Q值
Getting from Q-Network to Deep Q-Network
Addition 1: Convolutional Layers
Addition 2: Experience Replay
The basic idea is that by storing an agent’s experiences, and then randomly drawing batches of them to train the network, we can more robustly learn to perform well in the task.
Addition 3: Separate Target Network
at every step of training, the Q-network’s values shift, and if we are using a constantly shifting set of values to adjust our network values, then the value estimations can easily spiral out of control. The network can become destabilized by falling into feedback loops between the target and estimated Q-values. In order to mitigate that risk, the target network’s weights are fixed, and only periodically or slowly updated to the primary Q-networks values. In this way training can proceed in a more stable manner.
Double DQN
普通DQN通常高估特定state下的潜在actions的Q值,如果所有的actions都被平等的高估,倒也没啥问题,但是肯定不是这样的。因此DDQN提出了一个简单的技巧,不再取训练时目标Q值中最大Q值,我们使用原始的网络选择action,目标网络生成该action下的目标Q值。通过从生成的目标Q值中解耦action的选择,可以极大的降低高估情况,更快更有效的训练。更新目标值的公式为:
\[Q-Target = r + \gamma Q(s', \argmax (Q(s', a, \theta), \theta '))\]Dueling DQN
Regular DQN与Dueling DQN比较:
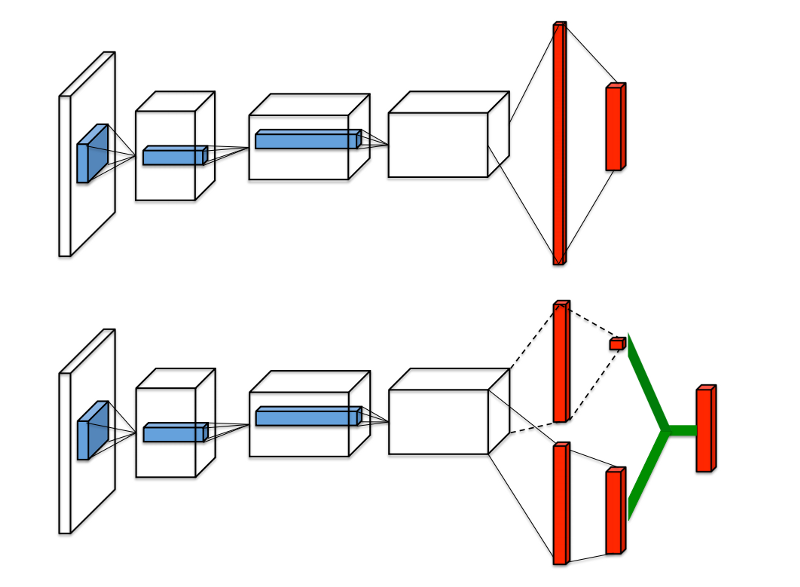
目前我们讨论的Q值表示在特定的state下采用某个action的好坏情况,可以记作 Q(s, a),可以分解为两个部分,一个是值函数 V(s),表示在某个给定的action下的好坏情况,另一个是优势函数 A(a),表示采取某个action与其他相比有多好。可以把Q看作是V和A的结合:
\[Q(s,a) = V(s) + A(a)\]Dueling DQN就是用网络分别计算优势函数和值函数,然后把他们结合起来。这样的好处是agent在任何时候不用关心值函数和优势函数。
综合起来

Simple block-world environment. The goal is to move the blue block to the green block while avoiding the red block.
from __future__ import division
import gym
import numpy as np
import random
import tensorflow as tf
import tensorflow.contrib.slim as slim
import matplotlib.pyplot as plt
import scipy.misc
import os
%matplotlib inline
from gridworld import gameEnv
env = gameEnv(partial=False,size=5)
"""Implementing the network itself"""
class Qnetwork():
def __init__(self,h_size):
#The network recieves a frame from the game, flattened into an array.
#It then resizes it and processes it through four convolutional layers.
self.scalarInput = tf.placeholder(shape=[None,21168],dtype=tf.float32)
self.imageIn = tf.reshape(self.scalarInput,shape=[-1,84,84,3])
self.conv1 = slim.conv2d( \
inputs=self.imageIn,num_outputs=32,kernel_size=[8,8],stride=[4,4],padding='VALID', biases_initializer=None)
self.conv2 = slim.conv2d( \
inputs=self.conv1,num_outputs=64,kernel_size=[4,4],stride=[2,2],padding='VALID', biases_initializer=None)
self.conv3 = slim.conv2d( \
inputs=self.conv2,num_outputs=64,kernel_size=[3,3],stride=[1,1],padding='VALID', biases_initializer=None)
self.conv4 = slim.conv2d( \
inputs=self.conv3,num_outputs=h_size,kernel_size=[7,7],stride=[1,1],padding='VALID', biases_initializer=None)
#We take the output from the final convolutional layer and split it into separate advantage and value streams.
self.streamAC,self.streamVC = tf.split(self.conv4,2,3)
self.streamA = slim.flatten(self.streamAC)
self.streamV = slim.flatten(self.streamVC)
xavier_init = tf.contrib.layers.xavier_initializer()
self.AW = tf.Variable(xavier_init([h_size//2,env.actions]))
self.VW = tf.Variable(xavier_init([h_size//2,1]))
self.Advantage = tf.matmul(self.streamA,self.AW)
self.Value = tf.matmul(self.streamV,self.VW)
#Then combine them together to get our final Q-values.
self.Qout = self.Value + tf.subtract(self.Advantage,tf.reduce_mean(self.Advantage,axis=1,keep_dims=True))
self.predict = tf.argmax(self.Qout,1)
#Below we obtain the loss by taking the sum of squares difference between the target and prediction Q values.
self.targetQ = tf.placeholder(shape=[None],dtype=tf.float32)
self.actions = tf.placeholder(shape=[None],dtype=tf.int32)
self.actions_onehot = tf.one_hot(self.actions,env.actions,dtype=tf.float32)
self.Q = tf.reduce_sum(tf.multiply(self.Qout, self.actions_onehot), axis=1)
self.td_error = tf.square(self.targetQ - self.Q)
self.loss = tf.reduce_mean(self.td_error)
self.trainer = tf.train.AdamOptimizer(learning_rate=0.0001)
self.updateModel = self.trainer.minimize(self.loss)
"""
Experience Replay
This class allows us to store experies and sample then randomly to train the network.
"""
class experience_buffer():
def __init__(self, buffer_size = 50000):
self.buffer = []
self.buffer_size = buffer_size
def add(self,experience):
if len(self.buffer) + len(experience) >= self.buffer_size:
self.buffer[0:(len(experience)+len(self.buffer))-self.buffer_size] = []
self.buffer.extend(experience)
def sample(self,size):
return np.reshape(np.array(random.sample(self.buffer,size)),[size,5])
def processState(states):
return np.reshape(states,[21168])
def updateTargetGraph(tfVars,tau):
total_vars = len(tfVars)
op_holder = []
for idx,var in enumerate(tfVars[0:total_vars//2]):
op_holder.append(tfVars[idx+total_vars//2].assign((var.value()*tau) + ((1-tau)*tfVars[idx+total_vars//2].value())))
return op_holder
def updateTarget(op_holder,sess):
for op in op_holder:
sess.run(op)
"""
Training the network
Setting all the training parameters
"""
batch_size = 32 #How many experiences to use for each training step.
update_freq = 4 #How often to perform a training step.
y = .99 #Discount factor on the target Q-values
startE = 1 #Starting chance of random action
endE = 0.1 #Final chance of random action
annealing_steps = 10000. #How many steps of training to reduce startE to endE.
num_episodes = 10000 #How many episodes of game environment to train network with.
pre_train_steps = 10000 #How many steps of random actions before training begins.
max_epLength = 50 #The max allowed length of our episode.
load_model = False #Whether to load a saved model.
path = "./dqn" #The path to save our model to.
h_size = 512 #The size of the final convolutional layer before splitting it into Advantage and Value streams.
tau = 0.001 #Rate to update target network toward primary network
tf.reset_default_graph()
mainQN = Qnetwork(h_size)
targetQN = Qnetwork(h_size)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
trainables = tf.trainable_variables()
targetOps = updateTargetGraph(trainables,tau)
myBuffer = experience_buffer()
#Set the rate of random action decrease.
e = startE
stepDrop = (startE - endE)/annealing_steps
#create lists to contain total rewards and steps per episode
jList = []
rList = []
total_steps = 0
#Make a path for our model to be saved in.
if not os.path.exists(path):
os.makedirs(path)
with tf.Session() as sess:
sess.run(init)
if load_model == True:
print('Loading Model...')
ckpt = tf.train.get_checkpoint_state(path)
saver.restore(sess,ckpt.model_checkpoint_path)
for i in range(num_episodes):
episodeBuffer = experience_buffer()
#Reset environment and get first new observation
s = env.reset()
s = processState(s)
d = False
rAll = 0
j = 0
#The Q-Network
while j < max_epLength: #If the agent takes longer than 200 moves to reach either of the blocks, end the trial.
j+=1
#Choose an action by greedily (with e chance of random action) from the Q-network
if np.random.rand(1) < e or total_steps < pre_train_steps:
a = np.random.randint(0,4)
else:
a = sess.run(mainQN.predict,feed_dict={mainQN.scalarInput:[s]})[0]
s1,r,d = env.step(a)
s1 = processState(s1)
total_steps += 1
episodeBuffer.add(np.reshape(np.array([s,a,r,s1,d]),[1,5])) #Save the experience to our episode buffer.
if total_steps > pre_train_steps:
if e > endE:
e -= stepDrop
if total_steps % (update_freq) == 0:
trainBatch = myBuffer.sample(batch_size) #Get a random batch of experiences.
#Below we perform the Double-DQN update to the target Q-values
Q1 = sess.run(mainQN.predict,feed_dict={mainQN.scalarInput:np.vstack(trainBatch[:,3])})
Q2 = sess.run(targetQN.Qout,feed_dict={targetQN.scalarInput:np.vstack(trainBatch[:,3])})
end_multiplier = -(trainBatch[:,4] - 1)
doubleQ = Q2[range(batch_size),Q1]
targetQ = trainBatch[:,2] + (y*doubleQ * end_multiplier)
#Update the network with our target values.
_ = sess.run(mainQN.updateModel, \
feed_dict={mainQN.scalarInput:np.vstack(trainBatch[:,0]),mainQN.targetQ:targetQ, mainQN.actions:trainBatch[:,1]})
updateTarget(targetOps,sess) #Update the target network toward the primary network.
rAll += r
s = s1
if d == True:
break
myBuffer.add(episodeBuffer.buffer)
jList.append(j)
rList.append(rAll)
#Periodically save the model.
if i % 1000 == 0:
saver.save(sess,path+'/model-'+str(i)+'.ckpt')
print("Saved Model")
if len(rList) % 10 == 0:
print(total_steps,np.mean(rList[-10:]), e)
saver.save(sess,path+'/model-'+str(i)+'.ckpt')
print("Percent of succesful episodes: " + str(sum(rList)/num_episodes) + "%")
"""
Checking network learning
Mean reward over time
"""
rMat = np.resize(np.array(rList),[len(rList)//100,100])
rMean = np.average(rMat,1)
plt.plot(rMean)